本文基于 kratos v2.1.3
设计理念
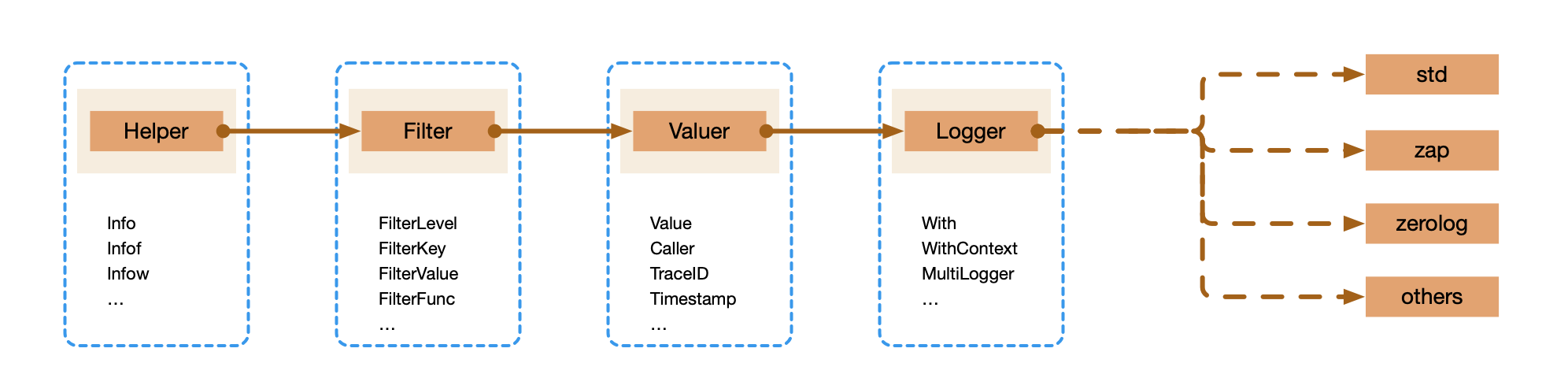
为了方便使用,Kratos 定义了两个层面的抽象,Logger 统一了日志的接入方式,Helper 接口统一的日志库的调用方式。
在不同的公司、使用不同的基础架构,可能对日志的打印方式、格式、输出的位置等要求各有不同。Kratos 为了更加灵活地适配和迁移到各种环境,把日志组件也进行了抽象,这样就可以把业务代码里日志的使用,和日志底层具体的实现隔离开来,提高整体的可维护性。
Kratos 的日志库主要有如下特性:
- Logger 用于对接各种日志库或日志平台,可以用现成的或者自己实现
- Helper 是在您的项目代码中实际需要调用的,用于在业务代码里打日志
- Filter 用于对输出日志进行过滤或魔改(通常用于日志脱敏等)
- Valuer 用于绑定一些全局的固定值或动态值(比如时间戳、traceID 或者实例 id 之类的东西)到输出日志中
整体调用关系如图所示:
日志接口
kratos 的日志库,不强制具体实现方式,只提供适配器,用户可以自行实现日志功能,只需要实现 Logger 接口即可接入自己的日志系统。
1
2
3
|
type Logger interface {
Log(level Level, keyvals ...interface{}) error
}
|
可以看到,接口定义很简单,只有一个 Log 方法,方法的的第一个参数 level 为日志级别,后面的 keyvals 参数即为我们的日志参数,它的长度需要是偶数,奇数位上的是 key,偶数位上的是 value。
快速接入
下面看下官方提供的 zap 库接入实例,只需要实现 Logger 接口即可:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
|
// https://github.com/go-kratos/kratos/blob/main/contrib/log/zap/zap.go
package zap
import (
"fmt"
"github.com/go-kratos/kratos/v2/log"
"go.uber.org/zap"
)
var _ log.Logger = (*Logger)(nil)
type Logger struct {
log *zap.Logger
}
func NewLogger(zlog *zap.Logger) *Logger {
return &Logger{zlog}
}
func (l *Logger) Log(level log.Level, keyvals ...interface{}) error {
if len(keyvals) == 0 || len(keyvals)%2 != 0 {
l.log.Warn(fmt.Sprint("Keyvalues must appear in pairs: ", keyvals))
return nil
}
var data []zap.Field
for i := 0; i < len(keyvals); i += 2 {
data = append(data, zap.Any(fmt.Sprint(keyvals[i]), keyvals[i+1]))
}
switch level {
case log.LevelDebug:
l.log.Debug("", data...)
case log.LevelInfo:
l.log.Info("", data...)
case log.LevelWarn:
l.log.Warn("", data...)
case log.LevelError:
l.log.Error("", data...)
case log.LevelFatal:
l.log.Fatal("", data...)
}
return nil
}
func (l *Logger) Sync() error {
return l.log.Sync()
}
|
源码分析
Level 日志等级
定义了五种日志等级,默认为 info 级别:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
// 日志级别类型
type Level int8
// 定义五种日志级别,默认是 info 级别
const (
LevelDebug Level = iota - 1 // debug 级别
LevelInfo // info 级别
LevelWarn // warn 级别
LevelError // error 级别
LevelFatal // fatal 级别
)
func (l Level) String() string {
switch l {
case LevelDebug:
return "DEBUG"
case LevelInfo:
return "INFO"
case LevelWarn:
return "WARN"
case LevelError:
return "ERROR"
case LevelFatal:
return "FATAL"
default:
return ""
}
}
|
Logger
在开头我们已经介绍了 Logger 接口的设计,接下来我们看下比较重要的结构体 logger:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
// 实现了 Logger 接口,所有的其他扩展功能都是基于此对象
type logger struct {
logs []Logger // 保存多个日志实例
prefix []interface{} // 保存公共 kv 参数
hasValuer bool // 标识是否包含动态参数值
ctx context.Context // 上下文
}
// 实现了 Logger 接口
func (c *logger) Log(level Level, keyvals ...interface{}) error {
// 注意:这里一定要 copy 一份新的 prefix 公共参数,防止在 bindValues 函数里面 prefix 参数被覆盖,造成对后续调用的值污染 !!!
kvs := make([]interface{}, 0, len(c.prefix)+len(keyvals))
kvs = append(kvs, c.prefix...)
if c.hasValuer {
bindValues(c.ctx, kvs) // 对于包含有动态值的情况,需要实时计算动态值
}
kvs = append(kvs, keyvals...)
// 写入多个日志实例
for _, l := range c.logs {
if err := l.Log(level, kvs...); err != nil {
return err
}
}
return nil
}
|
这里要注意:一定要 copy 一份新的 prefix 公共参数,防止在 bindValues 函数里面 prefix 参数被覆盖,造成对后续调用的值污染 !!!
logger 结构体照样实现了 Logger 接口,但提供了更丰富的扩展功能:
- logs:支持多日志输出实例,比如可以同时输出到终端和日志文件。
- prefix:切片类型,保存了公共的 kv 参数,对于后续每次调用日志接口都会记录。
- hasValuer:标识是否包含动态值参数,如果是 true 标识 prefix 里面包含动态值参数。
- ctx:绑定了上下文,方便获取 traceId、requestId 等请求信息。
Logger 的接口实现也比较简单,主要包含三个核心功能:
- 首先,合并公共参数和当前日志参数。
- 其次,判断是否有动态值,有的话需要实时计算出来该动态值。
- 最后,循环依次调用多个日志实例来写入。
下面我们依次来介绍。
1.多日志实例:
1
2
3
4
|
func MultiLogger(logs ...Logger) Logger {
return &logger{logs: logs}
}
|
实现比较简单,直接把 logs 放入 logger 结构体返回即可,值得注意的是返回值依然是 Logger 接口,完全面向接口设计。
2.注入 kv 参数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
func With(l Logger, kv ...interface{}) Logger {
// 如果是 *logger 对象的话,只需要添加 kv 参数和检查下是否包含动态值即可
if c, ok := l.(*logger); ok {
kvs := make([]interface{}, 0, len(c.prefix)+len(kv))
kvs = append(kvs, kv...)
kvs = append(kvs, c.prefix...)
return &logger{
logs: c.logs,
prefix: kvs,
hasValuer: containsValuer(kvs),
ctx: c.ctx,
}
}
// 包装成 *logger 对象,并检查是否包含动态值
return &logger{logs: []Logger{l}, prefix: kv, hasValuer: containsValuer(kv)}
}
|
With 方法第一个参数为 Logger 接口类型,第二个参数为 kv 切片类型,需要成对出现,奇数为 key,偶数为 value。
首先判断 l 是否为 *logger 类型:
- 如果是的话,会继承当前对象里面的参数,然后追加新增的公共 kv 参数,并检查下是否包含动态值即可。
- 如果不是的话,直接返回一个新的对象。
关于 containsValuer 函数的定义在下面会介绍👇🏻。
3.绑定 ctx 上下文:
1
2
3
4
5
6
7
8
9
10
11
12
|
// 绑定 ctx 上下文,ctx 不能为 nil
func WithContext(ctx context.Context, l Logger) Logger {
if c, ok := l.(*logger); ok {
return &logger{
logs: c.logs,
prefix: c.prefix,
hasValuer: c.hasValuer,
ctx: ctx,
}
}
return &logger{logs: []Logger{l}, ctx: ctx}
}
|
WithContext 方法第一个参数为需要绑定的 ctx 上下文对象,第二个参数为日志接口对象,
和上面 With 方法类似,首先判断 l 是否为 *logger 类型:
- 如果是的话,会继承当前对象里面的参数,只需覆盖里面的 ctx 值即可。
- 如果不是的话,直接返回一个新的对象。
Valuer
在业务日志中,通常我们会在每条日志中输出一些全局的字段,比如时间戳,实例 id,追踪 id 等,每次在日志输出中手动添加这些全局的参数比较麻烦,这时可以定义一个动态值,在每次日志输出时计算当前值。
Kratos 里面定义了 Valuer 动态值类型:
1
2
|
// 定义动态值回调方法类型,方便设置全局字段
type Valuer func(ctx context.Context) interface{}
|
本质是一个 function 类型,输入 ctx 参数,染回返回 interface{} 接口类型,下面看下具体是怎么用的。
1.获取时间戳
1
2
3
4
5
|
func Timestamp(layout string) Valuer {
return func(context.Context) interface{} {
return time.Now().Format(layout)
}
}
|
2.获取 Trace 信息
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
// TraceID returns a traceid valuer.
func TraceID() log.Valuer {
return func(ctx context.Context) interface{} {
if span := trace.SpanContextFromContext(ctx); span.HasTraceID() {
return span.TraceID().String()
}
return ""
}
}
// SpanID returns a spanid valuer.
func SpanID() log.Valuer {
return func(ctx context.Context) interface{} {
if span := trace.SpanContextFromContext(ctx); span.HasSpanID() {
return span.SpanID().String()
}
return ""
}
}
|
以上是官方库自带的方法,我们也可以根据业务场景自定义一些适合自己业务的全局方法。
介绍完了如何定义动态值方法,接下来看下是如何被调用的。
1.containsValuer 判断是否有动态值
1
2
3
4
5
6
7
8
9
|
// 通过断言为 Valuer 类型来确定是否包含动态值
func containsValuer(keyvals []interface{}) bool {
for i := 1; i < len(keyvals); i += 2 {
if _, ok := keyvals[i].(Valuer); ok {
return true
}
}
return false
}
|
实现比较简单,根据传进来的 kervals 参数来依次遍历 value 判断是否为 Valuer 类型即可。
2.bindValues 计算动态值
1
2
3
4
5
6
7
8
9
|
// 实时计算 kvs 参数里面对应的动态值
func bindValues(ctx context.Context, keyvals []interface{}) {
for i := 1; i < len(keyvals); i += 2 {
if v, ok := keyvals[i].(Valuer); ok {
keyvals[i] = v(ctx)
}
}
}
|
也是遍历 keyvals 参数依次来判断 value 是否为 Valuer 类型:
- 是的话,调用 Valuer 方法来计算动态值,并覆盖当前的 value 值;
- 不是的话,什么也不处理,保持 value 当前值即可。
注意:这里不用担心覆盖 keyvals 里面的 value 造成的污染问题,因为 keyvals 参数是一个副本,不会对全局公共参数 prefix 造成污染。
Filter
有时日志中可能会有敏感信息,需要进行脱敏,或者只打印级别高的日志,这时候就可以使用 Filter 来对日志的输出进行一些过滤操作,通常用法是使用 Filter 来包装原始的 Logger,用来创建 Helper 使用。
看下 Filter 结构体定义,已对各个参数做了注释:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
|
// 日志过滤组件,实现了 Logger 接口
// 有时日志中可能会有敏感信息,需要进行脱敏,或者只打印级别高的日志
// 这时候就可以使用 Filter 来对日志的输出进行一些过滤操作,通常用法是:
// - 使用 Filter 来包装原始的 Logger
// - 基于 Filter 实例用来创建 Helper
type Filter struct {
logger Logger // 保存需要实施过滤规则的日志组件
level Level // 需要保留的最低日志级别
key map[interface{}]struct{} // 需要遮掩的 key 列表
value map[interface{}]struct{} // 需要遮掩的 val 列表
filter func(level Level, keyvals ...interface{}) bool // 自定义过滤器
}
// 实例化对象
func NewFilter(logger Logger, opts ...FilterOption) *Filter {
options := Filter{
logger: logger,
key: make(map[interface{}]struct{}),
value: make(map[interface{}]struct{}),
}
for _, o := range opts {
o(&options)
}
return &options
}
// 实现了 Logger 接口
func (f *Filter) Log(level Level, keyvals ...interface{}) error {
// 检查是否需要过滤该日志级别
if level < f.level {
return nil
}
// 通过自定义过滤方法来检查是否需要过滤该日志
if f.filter != nil && f.filter(level, keyvals...) {
return nil
}
// 检查是否需要对 key 或者 val 进行遮掩
if len(f.key) > 0 || len(f.value) > 0 {
for i := 0; i < len(keyvals); i += 2 {
v := i + 1
if v >= len(keyvals) {
continue
}
// 检查 key
if _, ok := f.key[keyvals[i]]; ok {
keyvals[v] = fuzzyStr
}
// 检查 val
if _, ok := f.value[keyvals[v]]; ok {
keyvals[v] = fuzzyStr
}
}
}
// 至此才开始保存日志
return f.logger.Log(level, keyvals...)
}
|
首先,通过 NewFilter 函数来创建实例,第一个参数为日志实例,第二个为 FilterOption 类型动态参数:
1
2
3
4
|
FilterLevel(level Level) FilterOption: 指定日志级别,低于该等级的日志将不会被输出
FilterKey(key ...string) FilterOption: 需要脱敏的日志 key 列表,这些 key 的值会被 *** 遮蔽
FilterValue(value ...string) FilterOption: 需要脱敏的日志 val 列表,匹配的值会被 *** 遮蔽
FilterFunc(f func(level Level, keyvals ...interface{}) bool) FilterOption: 使用自定义的函数来对日志进行处理,keyvals 里为 key 和对应的 value,按照奇偶进行读取即可
|
其次,我们看下 Filter 是如何实现 Logger 接口的:
- 检查是否需要根据日志级别来进行过滤
- 检查是否有自定义过滤方法,有的话调用该方法,根据返回支持来判断是否需要过滤
- 检查 key 和 value 列表是否为空,不为空的话需要遍历 keyvals 来依次检查是否需要进行脱敏
- 最后调用 logger 进行日志的记录打印
Helper
Helper 为高级日志接口,提供了一系列带有日志等级和格式化方法的帮助函数,通常业务逻辑中建议使用这个,能够简化日志代码。
日常使用中,推荐通过 Logger 接口实例来进行参数传递,并在内部实例化为 Helper 对象来统一打印的行为。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
logger := With(DefaultLogger, "ts", DefaultTimestamp, "caller", DefaultCaller)
log := NewHelper(NewFilter(logger, FilterLevel(LevelDebug)))
// debug 日志会被过滤
log.Debug("test debug")
log.Debugf("test %s", "debug")
log.Debugw("log", "test debug")
// warn 日志会被打印
log.Warn("test warn")
log.Warnf("test %s", "warn")
log.Warnw("log", "test warn")
// 绑定 ctx 来打印
log.WithContext(ctx).Info("hello", "world")
|
使用方式
推荐的方式为,在程序启动入口处初始化 logger 实例:
1
2
3
4
5
6
7
8
9
10
11
|
logger := log.With(log.NewStdLogger(os.Stdout),
"ts", log.DefaultTimestamp,
"caller", log.DefaultCaller,
"service.id", id,
"service.name", Name,
"service.version", Version,
"trace_id", tracing.TraceID(),
"span_id", tracing.SpanID(),
))
logger = log.NewFilter(logger, log.FilterLevel(log.LevelDebug), log.FilterKey("password"))
|
这个 logger 将通过依赖注入工具 wire 的生成,注入到项目的各层中,供其内部使用。
下面我们拿 service 来举例看下,在这里将注入进来的 logger 实例用 log.NewHelper 包装成 Helper,绑定到 service 上,这样就可以在这一层调用这个绑定的 helper 对象来打日志了。
1
2
3
4
5
6
7
8
|
func NewGreeterService(uc *biz.GreeterUsecase, logger log.Logger) *GreeterService {
return &GreeterService{uc: uc, log: log.NewHelper(logger)} // 初始化和绑定 helper
}
func (s *GreeterService) SayHello(ctx context.Context, in *v1.HelloRequest) (*v1.HelloReply, error) {
s.log.WithContext(ctx).Infof("SayHello Received: %v", in.GetName()) // 打印日志
return &v1.HelloReply{Message: "Hello " + in.GetName()}, nil
}
|
其它几个层级的初始化和使用方式也是一样的,在 biz 层和 data 层中也可以按照这种方式来注入 logger。
小结
Kratos 为了更加灵活地适配和迁移到各种环境,把日志组件也进行了抽象,这样就可以把业务代码里日志的使用,和日志底层具体的实现隔离开来,提高整体的可维护性,用户只需要实现 Logger 接口即可接入自己业务场景的日志系统。
通过阅读日志组件源码,我们可以学习到,在开发系统组件或者业务逻辑时候,一定要面向接口编程进行松耦合设计,不要面向具体实现编程,才能提高系统的可维护性和高扩展性。
参考
https://github.com/go-kratos/kratos
https://github.com/go-kratos/kratos/issues/882