Prometheus学习笔记|00.简介与原理
第一次接触并使用 Prometheus 是在上家公司(QTT)做一个商城项目,当然只是简单的使用并未过多的深入了解、学习。到现在,Prometheus 已经是服务监控领域的标配了,是时候深入好好研究总结一下它了。
服务治理有一个指标叫做可观测性,主要包含监控、链路、日志三大方面,其中监控目前用的比较多的便是 Prometheus。
什么是 Prometheus
Prometheus 受启发于 Google 的 Brogmon 监控系统(相似的 Kubernetes 是从 Google 的 Brog 系统演变而来),从 2012 年开始由前 Google 工程师在 Soundcloud 以开源软件的形式进行研发,并且于 2015 年早期对外发布早期版本。2016 年 5 月继 Kubernetes 之后成为第二个正式加入 CNCF 基金会的项目,同年 6 月正式发布 1.0 版本。2017 年底发布了基于全新存储层的 2.0 版本,能更好地与容器平台、云平台配合。
下面便是其发展历程:
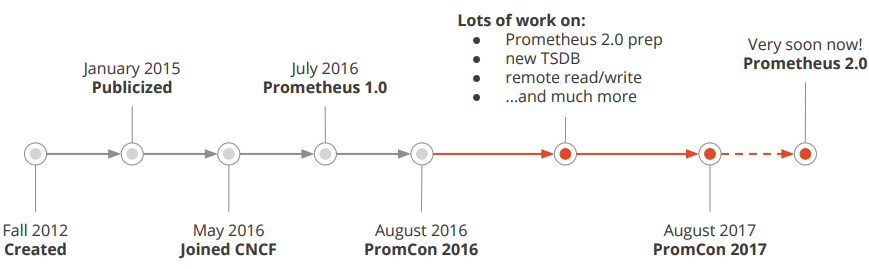
Prometheus 的优势
Prometheus 的主要优势有:
- 由指标名称和和键/值对标签标识的时间序列数据组成的多维数据模型。
- 强大的查询语言 PromQL。
- 不依赖分布式存储;单个服务节点具有自治能力。
- 时间序列数据是服务端通过 HTTP 协议主动拉取获得的。
- 也可以通过中间网关来推送时间序列数据。
- 可以通过静态配置文件或服务发现来获取监控目标。
- 支持多种类型的图表和仪表盘。
Prometheus 的组件
Prometheus 生态系统由多个组件组成,其中有许多组件是可选的:
- Prometheus Server 作为服务端,用来存储时间序列数据。
- 客户端库用来检测应用程序代码。
- 用于支持临时任务的推送网关。
- Exporter 用来监控 HAProxy,StatsD,Graphite 等特殊的监控目标,并向 Prometheus 提供标准格式的监控样本数据。
- alartmanager 用来处理告警。
- 其他各种周边工具。
大多数Prometheus组件都是用Go编写的,因此易于构建和部署为静态二进制文件。
Prometheus 的架构以及生态系统组件
直接看官方图:
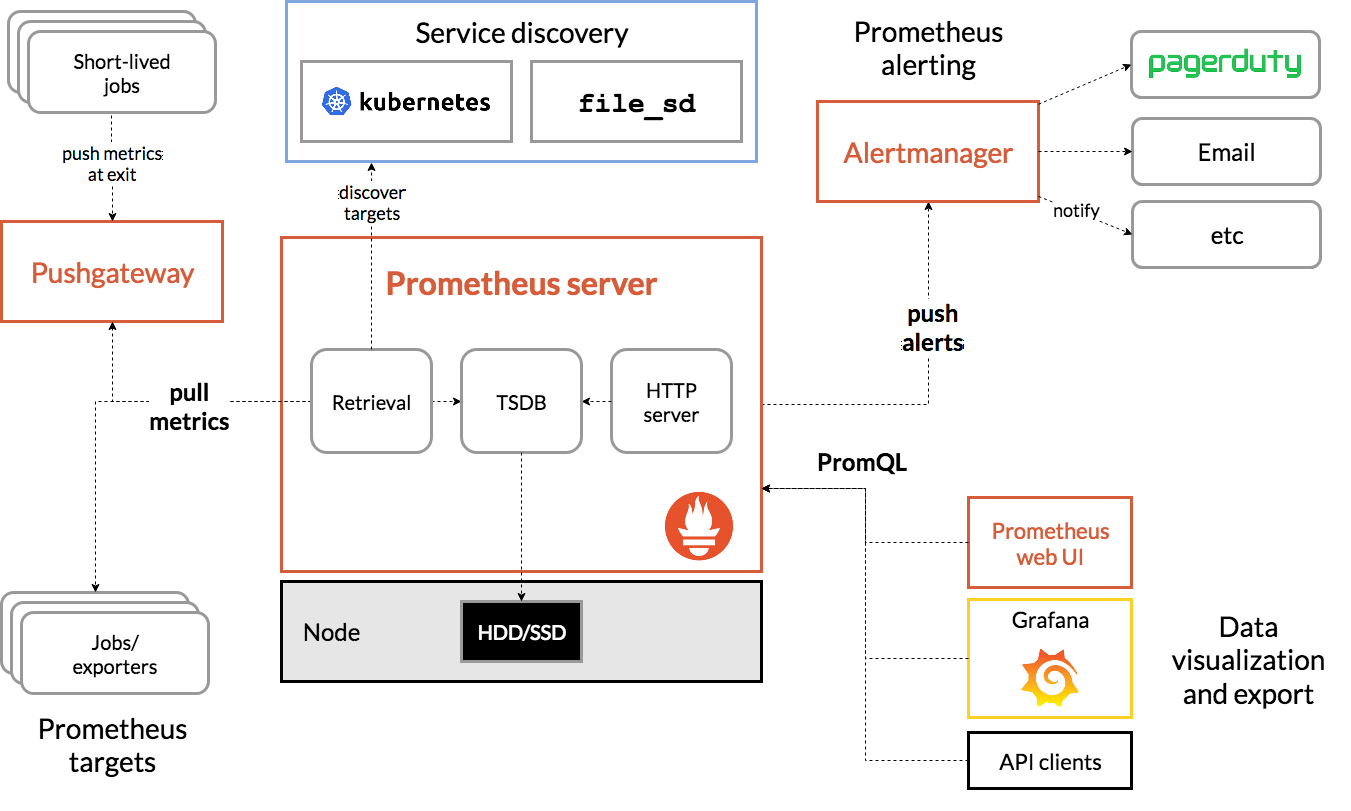
Prometheus Server 直接从监控目标中或者间接通过推送网关来拉取监控指标,它在本地存储所有抓取到的样本数据,并对此数据执行一系列规则,以汇总和记录现有数据的新时间序列或生成告警。可以通过 Grafana 或者其他工具来实现监控数据的可视化。
Prometheus 适用于什么场景
Prometheus 适用于记录文本格式的时间序列,它既适用于以机器为中心的监控,也适用于高度动态的面向服务架构的监控。在微服务的世界中,它对多维数据收集和查询的支持有特殊优势。Prometheus 是专为提高系统可靠性而设计的,它可以在断电期间快速诊断问题,每个 Prometheus Server 都是相互独立的,不依赖于网络存储或其他远程服务。当基础架构出现故障时,你可以通过 Prometheus 快速定位故障点,而且不会消耗大量的基础架构资源。
Prometheus 不适合什么场景
Prometheus 非常重视可靠性,即使在出现故障的情况下,你也可以随时查看有关系统的可用统计信息。如果你需要百分之百的准确度,例如按请求数量计费,那么 Prometheus 不太适合你,因为它收集的数据可能不够详细完整。这种情况下,你最好使用其他系统来收集和分析数据以进行计费,并使用 Prometheus 来监控系统的其余部分。
小结
对于工作多年的研发人员,对自己负责的系统必须了然于胸。而要做到了然于胸,单靠一味的自信是不够的,必须借助一套功能强大的业务监控系统。Prometheus 正是这么一套监控解决方案。它能让你随时掌控系统的运行状态,快速定位出现问题的位置,快速排除故障。
参考
https://prometheus.io/docs/introduction/overview/
- 原文作者:maratrix
- 原文链接:https://maratrix.cn/post/2021/02/08/prometheus-intro/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。